
V2: Recursive Descent Parser 2.0 - Java
Published:
Version 2: A Java program that analyzes the validity of an input files’ lexical syntax for a hypothetical imperative programming language, with a fully functional UI, specific error outputs with line number identification, and unit testing.
Introduction
Visit the blog post on the Recursive Descent Parser Version 1 for some background information on recursive descent parsing, the grammar used, symbols used, and example outputs for V1.
Tools & Techniques
- Java
- JavaFX
- Maven
- Eclipse IDE
- JUnit
- Mockito
Objective
Develop a Java program that analyzes the validity of an input files’ lexical syntax for a hypothetical imperative programming language, with a fully functional UI, specific error outputs with line number identification, and unit testing.
The implementation of the program follows the two steps below:
- Implement a lexical analyzer as a subprogram of the main program. Each time the lexical analyzer is called, it should return the next lexeme and its token code.
- Implement a parser based on the above Extended Backus-Naur Form (EBNF) rules. Create a subprogram for each nonterminal symbol which should parse only sentences that can be generated by the nonterminal.
What is RDP? Why I chose it
A Recursive Descent Parser (RDP) is a recursive program following a grammar that checks and validates syntax structure of a piece of code. RDPs are top-down parsers, where each recursive method implements one of the nonterminals in the grammar.
Key objectives of RDPs:
- Syntax Analysis: Ensures the input code follows the grammatical rules of the programming language
- Generates Abstract Syntax Trees: Constructs a tree representation of the source code that captures its syntactic structure
- Error Reporting: Identifies and reports syntax errors in the source code
Recursive descent parsers (RDPs) are not only valuable for syntax analysis but also serve as an effective learning exercise, as they incorporate multiple core programming concepts. Inspired by topics from a Programming Languages course I completed at university, I developed an interest in how RDPs function and undertook a project to build one for analyzing the syntax of input programs for a hypothetical imperative programming language. Through this project, I explored key programming concepts such as recursion, grammars, parse trees, and unit testing.
What is Recursion?
Direct recursion is the process of breaking problems down into smaller, identical problems until they become trivial to solve. There are two main sections to recursive functions in computer science: The Base Case, and The Recursive Case.
1) Base Case: a section of code that defines the smallest problem possible, provides a solution to this problem, and does not use recursion in the answer
2) Recursive Case: reduces each step in the recursive call until the Base Case is reached.
How is it used in this project?
- My parser uses recursive procedures to process input code
- If a parsing function encounters another non-terminal symbol while processing the input, it calls the corresponding parsing function recursively. This recursive call allows the parser to handle nested structures and complex grammatical constructs.
Grammar Logic
Terms:
- Extended Backus-Naur Form – A notation to express a context-free grammar
- Grammar – Describes which strings from a language alphabet are valid syntax
- Production Rules – Each line in a grammar is known as a production rule with the basic structure:
<nonterminal>→ with variations of terminal, nonterminal, operators and separator, symbols
- Nonterminals - Any symbols used in the grammar that can’t appear in the final strings. Every nonterminal subprogram only parses sentences that can be generated by the nonterminal.
- Terminals - Outputs from the grammar production rules. Terminal symbols cannot be changed.
To create this Grammar, all left recursion and left factoring was removed – so that the resulting grammar can be parsed by a recursive descent parser.
The grammar for this RDP can be seen below:
Nonterminals –> Each nonterminal is highlighted with pink underlines, and utilize the angled bracket notation. The <program> nonterminal parses the terminals: program, begin, and end, and the nonterminal <statement_list>, and only those. The parser for this specific grammar starts at the nonterminal symbol <program>. 
Terminals –> Terminals are highlighted in purple underlines and consist of program, begin, end, if, then, loop. 
Operators –> Operator symbols are highlighted in red underlines and consist of +, -, *, /, >, <. In this grammar, only the < and > logic symbols are included. 
Separators –> Separator symbols are highlighted in orange underlines and consist of: Or pipes | which signify an either or selection, curly brackets {} that denote optional statements with zero or more repetitions, parenthesis (), and semicolons ; to terminate statements. 
Parse Trees
Using grammars we can construct parse trees to show the execution of syntax structure for a specific program.
Parse Tree without errors –> In the image below, the parse tree on the right shows the hierarchical structure of the syntax on the left. Terminal nodes in the tree can be read from left to right: program → begin → test → = → 3 → end. 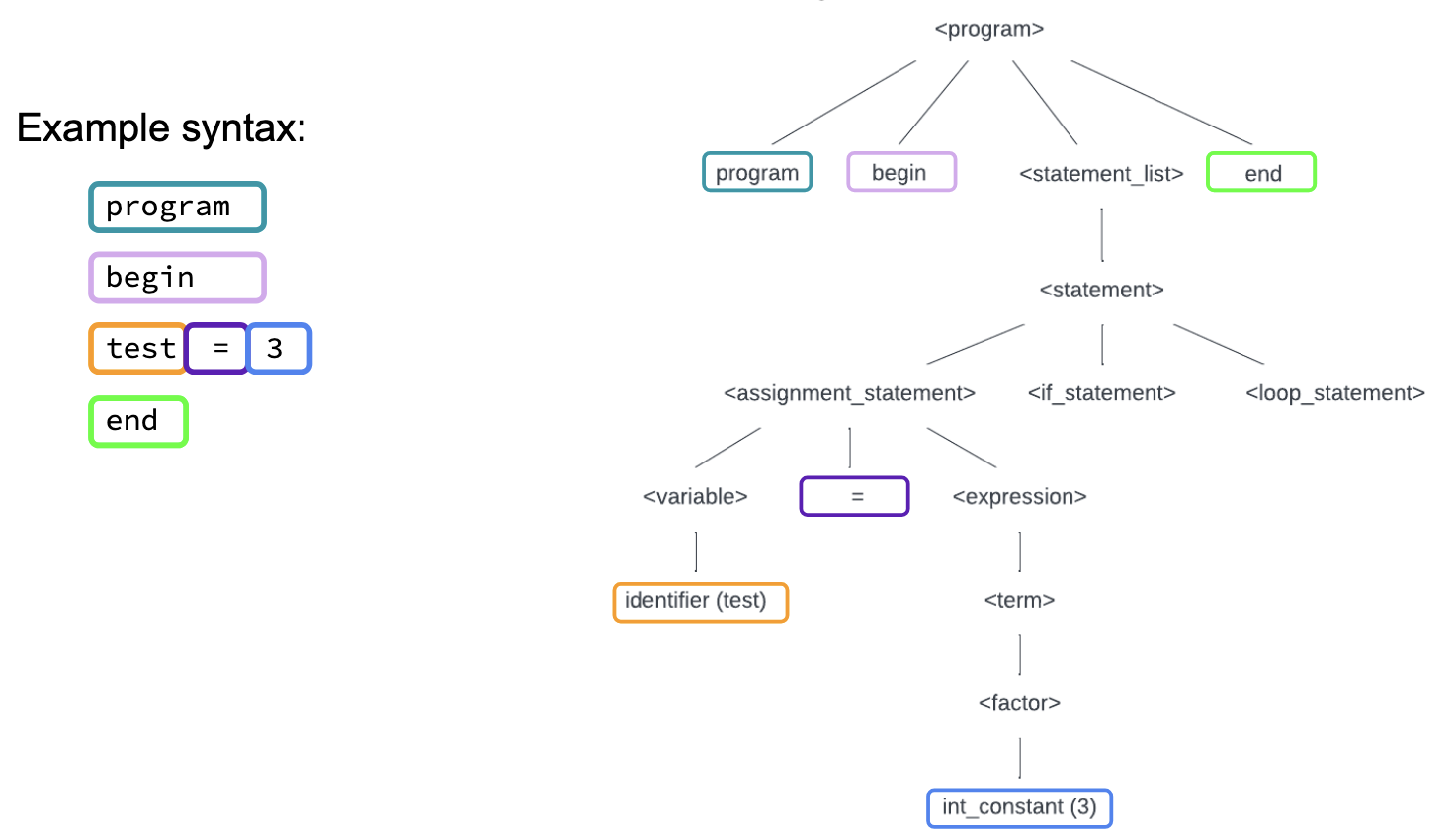
Parse Tree with errors –> Using the same example as above, let’s examine the parse tree with one minor change: a missing equals sign. The red box in the parse tree is where the parser expects to find an equal symbol to continue parsing the <assignment_statement>. A syntax error would output at this point. 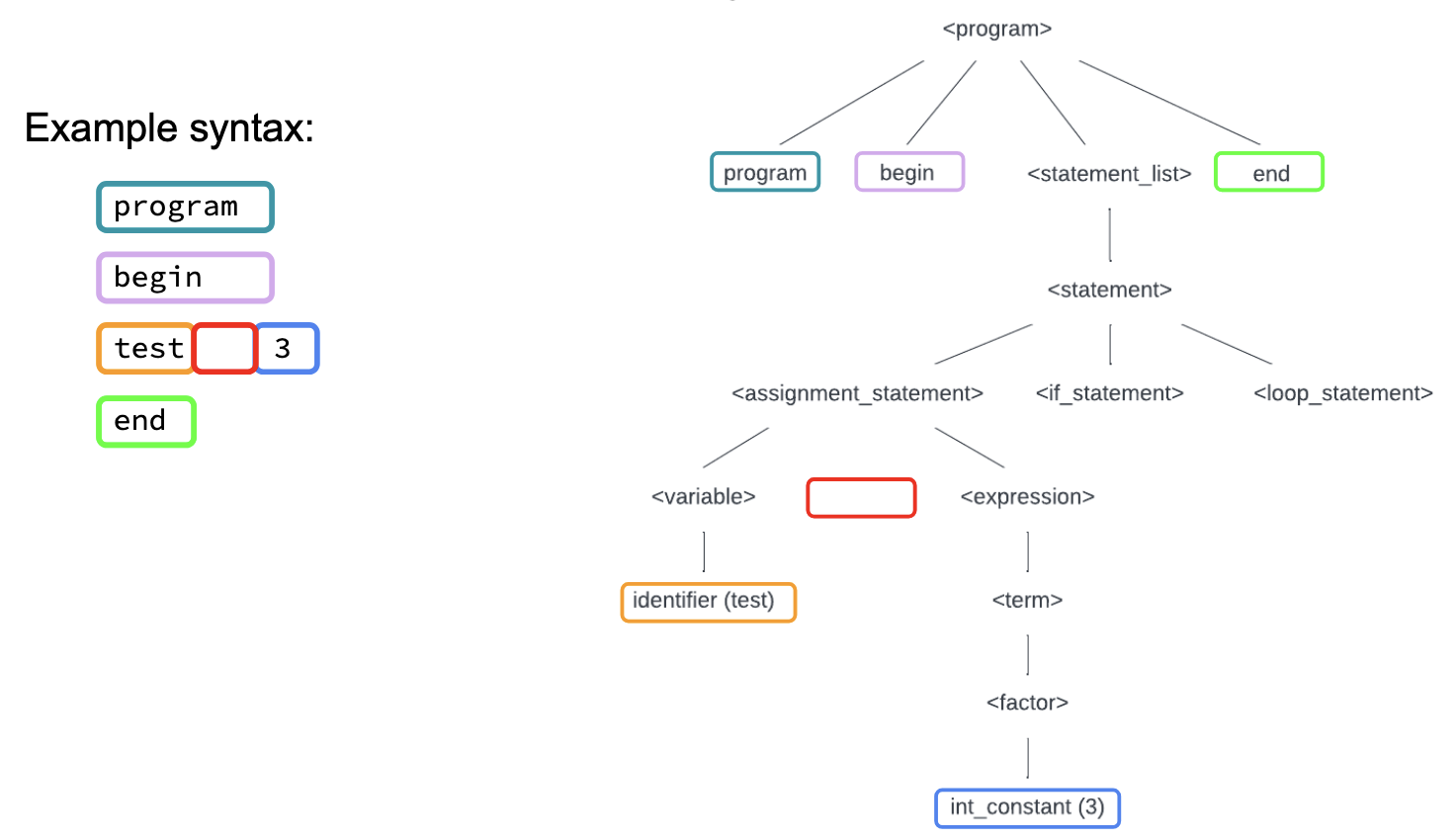
Unit Testing
In this project, I developed a set of functions to parse the syntax. To verify their functionality and ensure robustness, I employed unit testing throughout the development process. The frameworks used for unit testing to validate the expected behaviour of the parser’s functions is JUnit5 & Mockito.
- JUnit5 mainly uses the assertEquals method to validate function output
- Mockito is used to test void methods
Unit Testing –> Example output from a unit test on the getLex() function is shown below. Here we are testing the output of getLex() against a pre-set lexeme character array and testing for the expected output shown in the assertEquals method. 
Lifecycle
The development of the project has transformed from V1 to V2:
- V1 we have a Java Command Line application as the Minimum Viable Product and features a command line interface with text file input and an output of the presence or absence of syntax errors in the console
- V2 contains the development of a fully functional, interactive UI, specific error output with error type, line number identification in error message output, and unit testing
V2 UI Features:
- JavaFX (and Maven for build automation & project management) was used so users can input information into TextFields, TextAreas, and Buttons to perform syntax validation
- Functionalities
- Filename field – allows String input without file extension and automatically applies a .txt extension
- Codebox – accepts code syntax
- Checkmark – text component that displays only when syntax is parsed correctly
- Syntax error log – outputs errors readonly
- Submit button – handles creating and writing the code to file, and starting the parser
- Clear button – handles clearing the form inputs and checkmark
V1-V2 –> The transition from V1 to V2’s UI functionality. 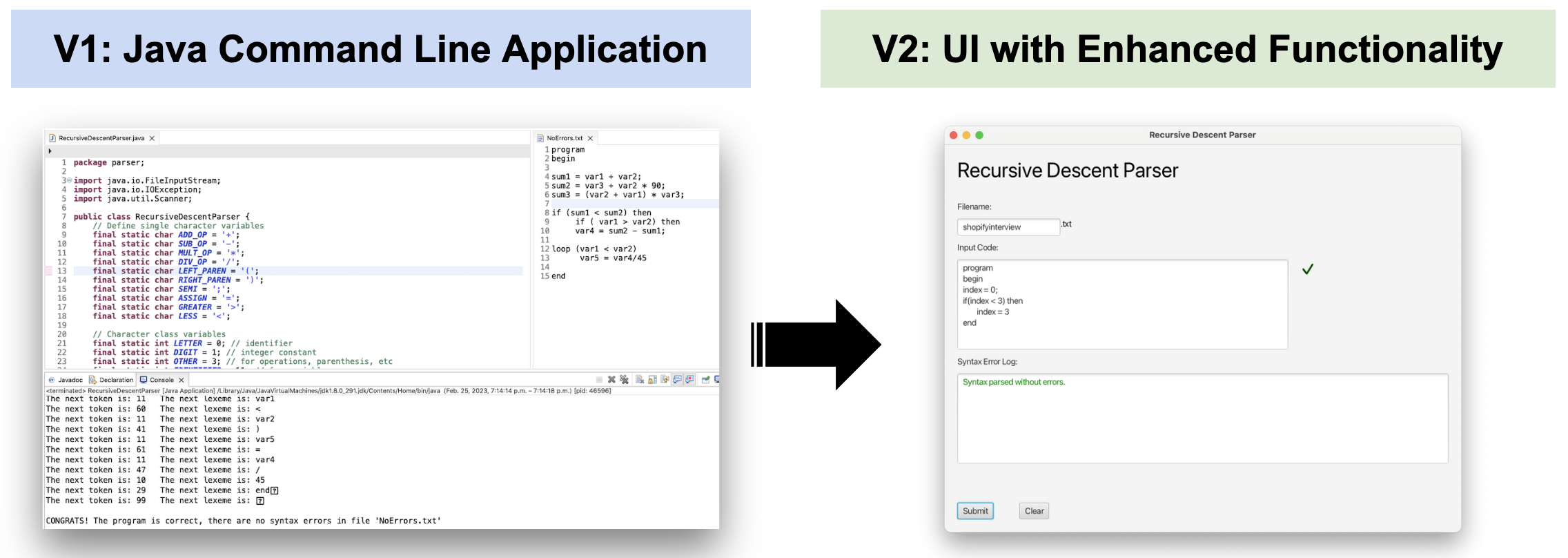
UI Breakdown
V2 Syntax Error Highlighting –> The V2 syntax error highlighting is shown below. 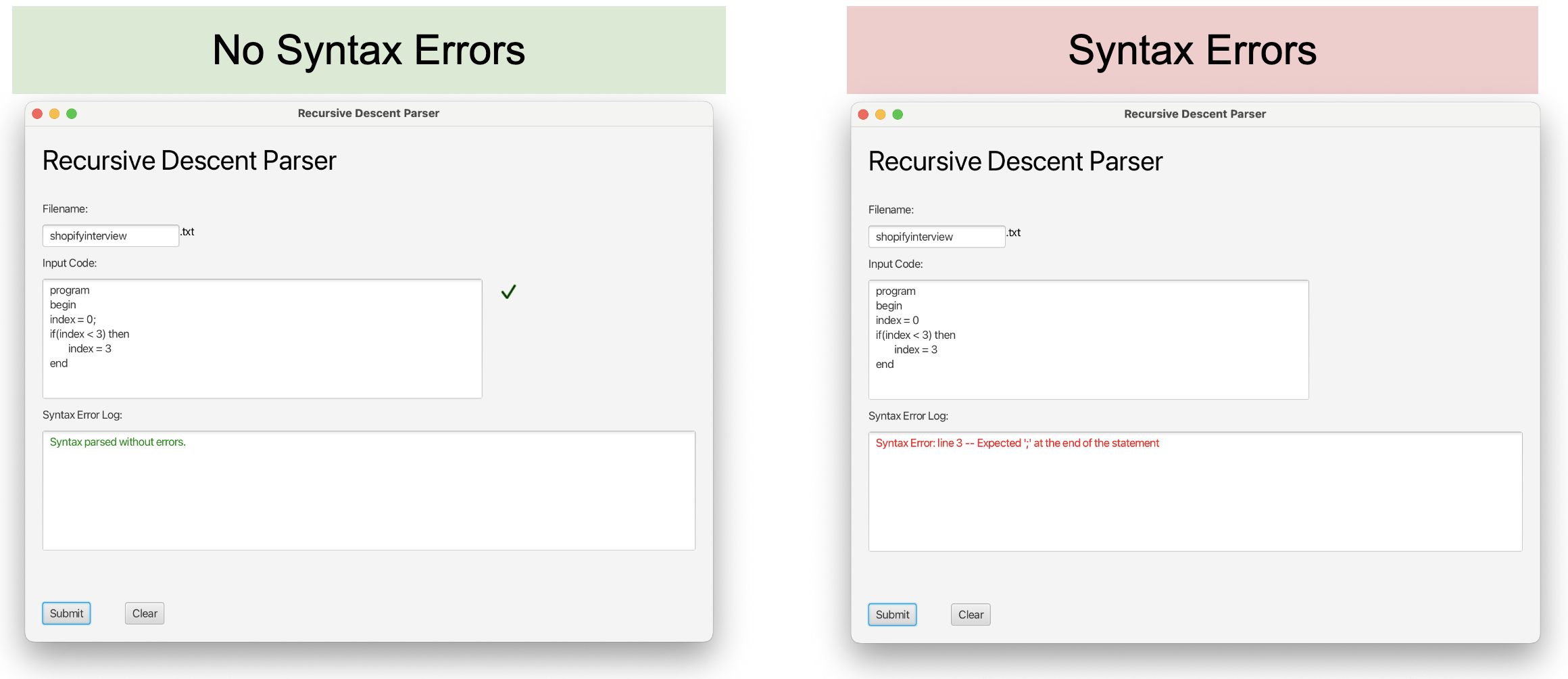
Future Development
This program has progressed from V1: a Java command line application to V2: UI implementation with enhanced functionality, here’s what V3 might bring:
- In-text error highlighting for underlining or changing color of syntax with errors – convert the code area to RichText to allow for this
- Line number in the code TextArea – convert the code area to RichText to allow for this
- Implement unit testing for all functions in the parser
- Implement a compiler to translate the syntactic source code into machine code
- Implement more rules to the Grammar to make a more robust syntactical structure. For example, expand on the logical operators to add greater than or equal to, less than or equal to
- Feature Addition: Accepting a filepath as input in the UI to read and edit an existing code file
Retrospective Project Analysis
In hindsight, there are several aspects I would approach differently, including:
- Consider implementing parser in a different programming language
- For example: Python due to its simplistic syntax that is highly readable, dynamic typing which can make parser code base much more concise, extensive standard library and third-party modules, and its prototyping and development abilities due to its high-level nature. However, Python has slower execution speed compared to compiled languages
- Implement a more robust UI using Java Swing (or Python UI framework)
- Unit test earlier in production of the program before implementation of all methods
- This would allow for early detection of problems in the development lifecycle
- Consider implementing a different parser type:
- LALR (Look-Ahead Left-to-Right) parser - These types of parsers strike a good balance between power and memory efficiency needed for practical use.
- Eliminate the need to write and read from file – in V1 code is read from file to check syntax, V2 carries this forward by first writing contents to file then reading. Could eliminate it entirely and use the code in the textbox to verify code syntax.
Run
To execute the program, follow the instructions below:
- Clone the git repo:
https://github.com/erincameron11/recursive-descent-parser - Open up the files as a Java project in the IDE of your choice.
- Run the
RecursiveDescentParser.javafile and follow the commands in the console.- _Note: When entering a file name in the console, do not put the file extensions (in this case,
.txt). For example:NoErrorsis a valid file name entry in the console.
- _Note: When entering a file name in the console, do not put the file extensions (in this case,